← WISSENS-BLOG
Wie ich eine klassische FAQ semantisch mit ExpressionEngine und JSON-LD erweitert habe
Wie strukturiert man eine FAQ so, dass sie nicht nur für Besucher verständlicher wird, sondern auch für KI-Systeme und semantische Suche interessanter? In diesem Praxisartikel zeige ich Schritt für Schritt, wie aus einer klassischen Accordion-FAQ mit ExpressionEngine eine kleine semantische Wissensstruktur entstanden ist — inklusive JSON-LD, semantischen Beziehungen, direkten Abschnittslinks und der Arbeits-Erkenntnis, dass weniger strukturierte Daten oft sinnvoller sind als immer komplexe SEO-Taxonomien.

Zuerst: Das ist kein „SEO-Tutorial“, sondern ein praktisches Beispiel dafür, wie semantische Wissensstrukturierung auch im kleinen Rahmen und von vorneherein aussehen kann.
Ausgangslage: Die FAQ war eigentlich schon gar nicht schlecht
Die ursprüngliche FAQ bestand bereits aus einer vergleichsweise sauberen HTML-Struktur:
<dl>
<dt>Frage</dt>
<dd>Antwort</dd>
</dl>
Damit war die FAQ semantisch bereits deutlich besser aufgebaut als viele typische Accordion-Lösungen, die ausschließlich aus verschachtelten <div>-Containern bestehen.
Auch die einzelnen Fragen waren direkt per Anchor-Link ansprechbar: Dadurch konnten einzelne FAQ-Einträge direkt verlinkt werden:
<a href="faq-barrierefreie-websites-bfsg#definition">Direktlink</a>
Allein das ist in vielen FAQ-Systemen noch erstaunlich selten.
Der nächste Schritt: strukturierte Daten für die FAQ
Die eigentliche Überlegung begann mit der Frage: Wie lässt sich diese FAQ zusätzlich als strukturierte Wissensstruktur im JSON-LD abbilden? Die erste Erweiterung war vergleichsweise naheliegend:
"mainEntity":[
{
"@type":"Question",
"name":"Was ist eine barrierefreie Website?",
"acceptedAnswer":{
"@type":"Answer",
"text":"..."
}
}
]
Damit wurde aus einer reinen HTML-FAQ zusätzlich eine maschinenlesbare Struktur.
Interessant ist dabei vor allem die Frage, warum hier überhaupt mit @type gearbeitet wird und warum der Typ Question gewählt wurde.
Genau das ist nämlich die eigentliche Idee hinter Schema.org und JSON-LD: Inhalte sollen nicht nur dargestellt, sondern auch semantisch beschrieben werden. Systeme wie Suchmaschinen oder KI-Anwendungen sollen verstehen können, was ein Inhalt überhaupt ist.
Eine Überschrift ist zunächst nur Text. Eine Frage innerhalb von JSON-LD dagegen wird explizit als semantisches Objekt beschrieben:
"@type":"Question"
Damit wird für Maschinen klar:
Dies ist keine gewöhnliche Textpassage, sondern eine Frage mit einer dazugehörigen Antwort.
Ebenso beschreibt:
"@type":"Answer"
die eigentliche Antwort als eigenes semantisches Objekt.
Schema.org arbeitet also mit Typen, die reale Wissensobjekte modellieren:
- Question
- Answer
- Article
- Person
- Event
- Product
und viele weitere.
Die Auswahl dieser Typen ist entscheidend. Genau hier entstehen sinnvolle semantische Beziehungen — oder eben redundante Metadaten.
Zunächst lag deshalb die Überlegung nahe, die gesamte Seite einfach als FAQPage auszuzeichnen. Diesen Typ gibt es in Schema.org tatsächlich.
Für diesen Anwendungsfall erschien jedoch die Kombination aus:
TechArticleQuestionAnswer
interessanter.
Warum?
Weil die Seite nicht nur aus einer FAQ besteht, sondern zugleich ein umfangreicher Fachartikel über digitale Barrierefreiheit ist. Die einzelnen FAQ-Einträge wurden deshalb nicht als isolierte FAQ-Seite verstanden, sondern als Wissenseinheiten innerhalb eines größeren Artikels.
Genau an solchen Stellen zeigt sich, dass semantische Strukturierung nicht bedeutet, möglichst viele strukturierte Daten auszugeben. Entscheidend ist vielmehr die Frage:
Welche Typen beschreiben den tatsächlichen Charakter der Inhalte möglichst präzise?
Die nächste Frage: Reicht Frage und Antwort wirklich aus?
An diesem Punkt wurde es interessant für mich. Denn technisch war die FAQ damit bereits korrekt ausgezeichnet. Trotzdem fehlte für mich zuerst intuitiv die eigentliche Wissensstruktur. Daraus ergab sich die Frage: Welche zusätzlichen Informationen wären semantisch sinnvoll?
Die erste Idee: Kategorien
Zunächst lag ein klassisches Kategorienfeld nahe. Zum Beispiel:
- Technik
- Gesetz
- Accessibility
- CMS
Doch genau hier entstand das erste Problem: Die meisten Kategorien wiederholten lediglich Informationen, die ohnehin bereits in Frage und Antwort enthalten waren.
Eine FAQ wie:
„Was bedeutet WCAG 2.1?“
trägt ihre thematische Einordnung bereits in sich. Zusätzliche Kategorien erzeugten deshalb kaum neue semantische Beziehungen. Die Struktur wurde komplexer, aber nicht intelligenter. Das Kategorienfeld wurde deshalb wieder verworfen.
Die Arbeitserkenntnis: Verdichtung statt Schlagwortwolken
Am Ende blieben zwei zusätzliche Felder übrig, die tatsächlich sinnvoll erschienen:
1. FAQ-Abstract
Das erste Feld war eine kurze semantische Verdichtung der eigentlichen Antwort. Aber nur aus dem Grund, weil die Antworten meistens recht lang sind. Dieses Feld erfüllt mehrere Aufgaben gleichzeitig:
- schnellere Orientierung für Besucher
- semantische Verdichtung
- bessere maschinenlesbare Zusammenfassungen
- klarere Struktur innerhalb langer FAQ-Antworten
Die Kurzantwort wurde dabei nicht nur im JSON-LD verwendet, sondern zusätzlich sichtbar oberhalb der eigentlichen Antwort eingebunden.
Dadurch stimmen sichtbare Struktur und strukturierte Daten erstmals wirklich überein. Und schließlich dienen strukturierte Daten nicht dazu, komplette Fließtexte einfach in JSON-LD zu kopieren. Viel sinnvoller ist die Frage, ob Inhalte bereits redaktionell so aufgebaut sind, dass sich ihr Kern in kurzen, klaren und maschinenlesbaren Zusammenfassungen darstellen lässt. Genau daraus entstehen am Ende die wirklich interessanten Wissensstrukturen.
Die zweite Erweiterung: verwandte Wissensobjekte
Der zweite interessante Schritt war etwas schwieriger. Meine ursprüngliche Überlegung lautete: Welche verwandten Konzepte stehen eigentlich in inhaltlicher Beziehung zur jeweiligen FAQ-Antwort?
Zum Beispiel:
- WCAG 2.1
- BITV
- WAI-ARIA
Zunächst entstand die Versuchung, diese Begriffe einfach als keywords auszugeben.
Aber damit war ich nicht zufrieden. Denn Keywords beschreiben eher Schlagwörter oder Suchbegriffe als tatsächliche fachliche Beziehungen.
Somit ersetzte dann die eine Idee eine andere: Wenn eine FAQ das Barrierefreiheitsstärkungsgesetz behandelt, stehen bestimmte Begriffe nicht zufällig daneben, sondern in realer inhaltlicher Beziehung dazu. Das BFSG ist beispielsweise die deutsche Umsetzung des European Accessibility Act. Die technische Umsetzung digitaler Barrierefreiheit orientiert sich wiederum an Standards wie WCAG 2.1 oder EN 301 549.
Zwischen diesen Begriffen bestehen also tatsächliche fachliche Zusammenhänge.
Genau diese Beziehungen sollten sichtbar gemacht werden.
Die bessere Lösung war deshalb schließlich:
"about":[
{
"@type":"Thing",
"name":"WCAG 2.1"
},
{
"@type":"Thing",
"name":"BITV"
}
]
Dadurch entstanden erstmals echte Beziehungen zwischen einzelnen Wissensobjekten.
Die FAQ bestand nun nicht mehr nur aus isolierten Fragen und Antworten, sondern begann, kleine fachliche Kontexte abzubilden. Genau hier wurde aber auch deutlich, dass solche Strukturen nicht einfach automatisch entstehen.
Denn die Auswahl verwandter Begriffe ist keine rein technische Aufgabe. Sie erfordert redaktionelle Entscheidungen. Nicht jeder Begriff passt automatisch zu jeder Frage. Und nicht jede mögliche Verbindung ist wirklich sinnvoll.
Gerade an diesem Punkt zeigt sich, dass strukturierte Wissensmodelle nicht einfach durch möglichst viele Metadaten entstehen. Entscheidend ist vielmehr die Qualität der inhaltlichen Beziehungen.
Natürlich können KI-Systeme dabei helfen, passende Konzepte oder angrenzende Themen vorzuschlagen. Trotzdem bleibt menschliche Prüfung wichtig. Denn nur durch echtes Mitdenken entsteht am Ende eine Struktur, die nicht bloß technisch korrekt ist, sondern auch fachlich nachvollziehbar.
Die praktische Grenze: CMS-Struktur
Spätestens an diesem Punkt zeigte sich ein typisches Problem der ernsthaften Inhaltsstrukturierung (semantischer Modellierung): Die Theorie ist einfacher als die CMS-Realität. Denn innerhalb eines FAQ-Gridfeldes ließ sich nicht ohne Weiteres ein weiteres Gridfeld verschachteln.
Die pragmatische Lösung bestand deshalb darin, zwei feste Felder anzulegen:
faq_verwandt
faq_verwandt2
So konnten verwandte Wissensobjekte weiterhin sauber gepflegt und als einzelne Thing-Objekte im JSON-LD ausgegeben werden, ohne die bestehende FAQ-Struktur unnötig kompliziert zu machen.
Und wie diese erweiterte FAQ-Struktur schließlich direkt im CMS aussieht, zeigt der folgende Screenshot. Überforderung für Redakteure sollte hier nicht entstehen. ;)
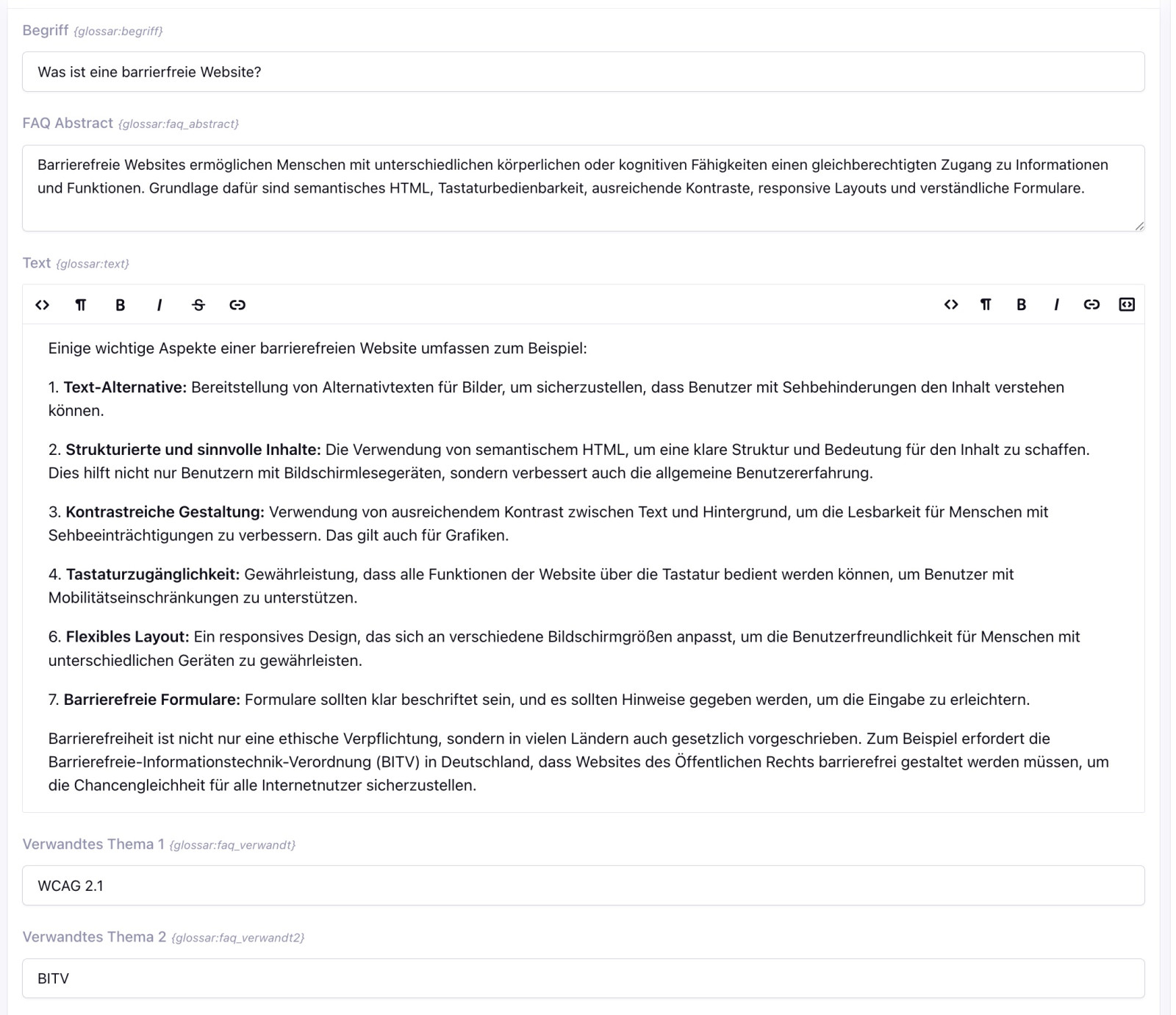
Ein oft übersehener Punkt: direkte Links auf einzelne FAQ-Einträge
Besonders spannend wurde schließlich die Kombination aus:
- Anchor-Links
- Accordion-Struktur
- JSON-LD
Denn jeder FAQ-Eintrag besitzt nun zusätzlich eine eigene URL:
"@type":"Question",
"name":"{glossar:begriff}",
"url":"{site_url}segertblog/{url_title}#{glossar:anker}",
"acceptedAnswer":{
"@type":"Answer",
"text":"{glossar:faq_abstract}"
Dadurch entstehen direkt adressierbare Wissenseinheiten innerhalb einer einzelnen Seite.
Das ist semantisch deutlich interessanter als klassische FAQ-Blöcke, die nur als geschlossener Gesamttext funktionieren.
Echte Wissensstrukturen entstehen nicht automatisch durch möglichst viele strukturierte Daten. Moderne Websites erzeugen oft große Mengen an Kategorien, Tags, Keywordfeldern und JSON-LD-Blöcken, ohne dass Inhalte dadurch wirklich verständlicher oder besser miteinander verbunden werden. Entscheidend ist vielmehr, ob zwischen Themen nachvollziehbare Beziehungen entstehen, Inhalte sinnvoll verdichtet werden und einzelne Wissensbereiche gezielt vertieft und miteinander verknüpft werden können.
Auch hier gilt zunächst: Weniger ist oft mehr. Für den Einstieg erwies sich eine kleinere, logischere Struktur als wesentlich sinnvoller — bestehend aus eigentlichen Fragen, kurzen Verdichtungen der Inhalte, nachvollziehbaren fachlichen Beziehungen, direkt verlinkbaren Wissenseinheiten und einer internen Verlinkung, die zusätzliche Kontexte zwischen den Themen herstellt. Genau in dieser Verbindung aus Struktur, Orientierung und Vernetzung könnte ein wesentlicher Teil der zukünftigen Entwicklung moderner Wissens- und Informationsseiten liegen.
Was mir dabei auffällt: Der gute alte Hypertext bekommt anscheinend ein Stück seiner ursprünglichen Bedeutung zurück. Inhalte stehen nicht mehr nur isoliert nebeneinander, sondern werden wieder stärker über Beziehungen, Verweise und Kontexte miteinander verbunden. Auch darin könnte künftig ein wesentlicher Unterschied zwischen bloß veröffentlichten Informationen und tatsächlich verständlich strukturiertem Wissen liegen. Ich bin dabei.
Blog-Startseite /// Rubrik KI-Sichtbarkeit